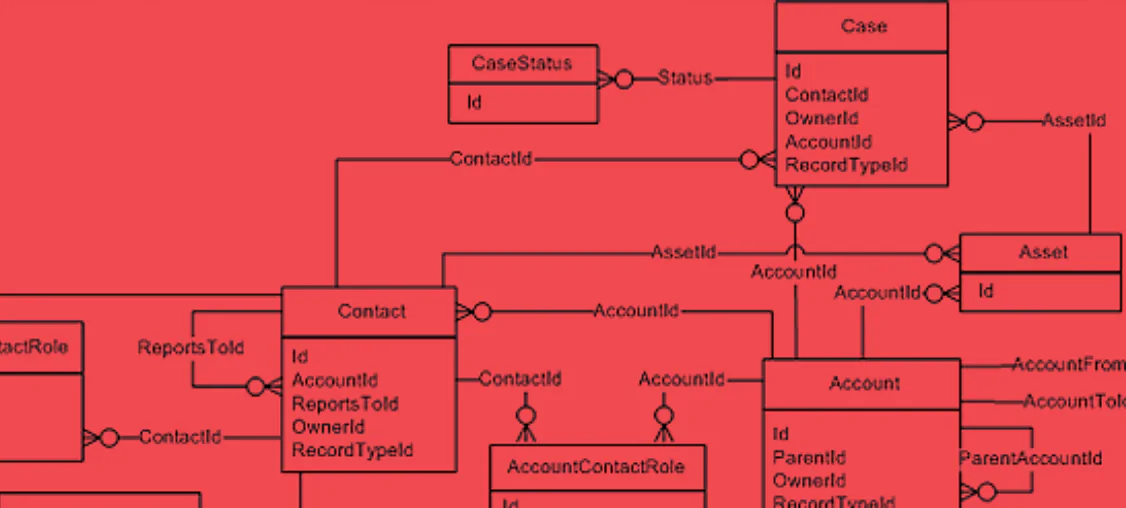
There’s a thin line between having your Salesforce end up as a glorified ‘dumb database’ where data entry is considered as an overhead vs. a smart, real-time insight generating database where data entry is considered worthwhile given the analytics it generates.
If the above sounds familiar to you and you’re getting anxious to know the “secret Salesforce sauce” that causes all the difference, then this post is for you.
As someone rightly said, “You are only as strong as your foundation.” In order to realise your Salesforce investments’ worth, you need to get your foundation design RIGHT, which in Salesforce’s case is the Data Model.
Before we get to the secrets of getting your Salesforce Data Model design done right, let’s reiterate WHY Data Model design so important.
- Data Model designing is critical and understanding reporting requirements UP-FRONT is a key success factor.
- Easy configuration is a double-edged sword and most of the time Data Models are set up by accidental Admins or Junior Functional Consultants who do not necessarily understand the impact that design has on the end result of Salesforce aligning to the overall vision/analytic dreams/security & performance needs.
- Traditional Data Model design principles where normalisation is the norm don’t work in Salesforce as calculated decisions need to be made by weighing tradeoff between user-experience (ease of inputting data) vs reporting requirements and deciding whether to normalise or denormalise.
- Good outcomes and bad outcomes start with the Data Model, your physical Data Model in Salesforce directly influences what is possible with Declarative Features vs what requires custom development.
So here are my Top 10 Secrets to Smartly Designing Your Salesforce Database
1. Go Top to Bottom when designing a Data Model:
- first understand the Vision/Challenges/Pain Points,
- then understand Reporting/Integration/Security/Performance needs
- and then finally design and build the Data Model.
2. In order to understand when to go flat (de-normalise) or not to go flat (normalise), let's consider the below user stories:
User Story #1 - NOT FLAT:
AS A Sales Manager I WANT to track commission percentages for all the sales reps working towards getting sales closed as per their individual contributions SO THAT I can generate an important KPI report showing Commission Share Per Consultant Per Quarter.
From the story we pick up, we are able to derive the following specific needs:
- Analytics Needs - A real-time report showing commission share per sales rep per quarter
- User Experience Needs - Able to log commission percentages per consultant per sale
Here data can be modelled in two ways (green and red):
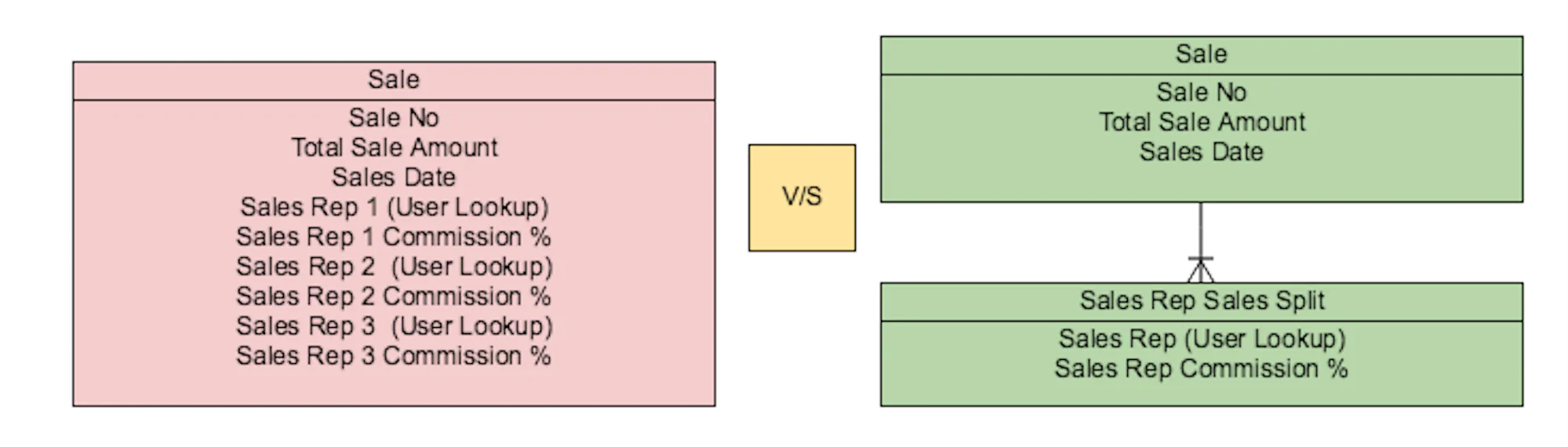

The focus of this user story is on the analytics needs, so from a reporting perspective, it makes sense to store Sales Rep’s split % into a separate table of its own (normalise/not go flat) because, now we can easily build a report to generate metrics like commission share per rep per quarter in minutes time by using report type Sales with Sales Rep Splits and grouping columns by sales rep and columns by sales date (grouped by quarter).
Now let’s take the second user story to understand when to go flat.
User Story #2 - FLAT:
AS A Sales Executive I WANT to easily enter mobile/fax/home contact numbers for a Lead SO THAT I can quickly find contact numbers when looking at lead record page, list views & reports and establish contact.
From the story we pick up, we are able to derive below specific needs.
- Analytics Needs - N/A
- User Experience Needs - Able to easily enter contact number on lead and see them on record page, list view and reports.
Here also Data can be modelled in below two ways,
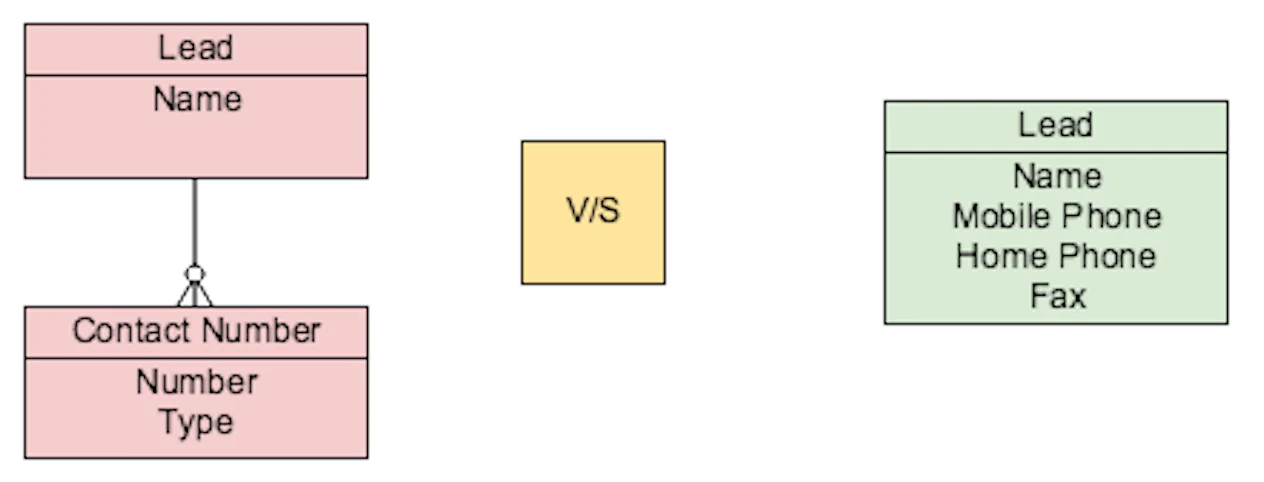

But here, as we don't have any specific analytic needs on contact numbers, instead the focus is on the user experience in entering and viewing the data. So here it makes sense to go flat and simply create fields of phone data type on Lead itself, so that those fields can then be easily added to the list views built on Lead object.
3. Understand cardinality in Salesforce (1:1, 1:n & m:n)
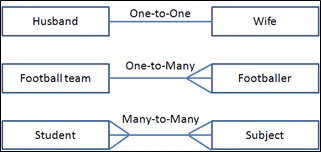
Create Lookup/MasterDetail to achieve 1:1 & 1:n & Create an additional junction object to achieve many to many relationships
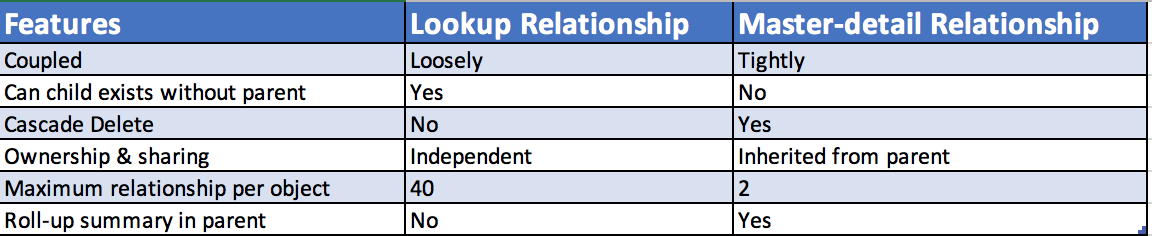
4. Wisely select the right type of relationship between objects:
There are two types available to build relationship between objects. Use the table below to understand when to use which:
5. Need rollups?
Let’s consider you have built a lookup relationship but still desperately need rollup fields, worry not – there are many AppExchange packages like Rollup Helper and open source code projects like the one here which I built available for your rescue.
6. Understand when to leverage standard objects vs. when to build a custom object:
Start with understanding the Salesforce Standard Objects and fields and their ‘Special Features’:
- If it walks like a duck and talks like a duck, it’s probably a duck.
- If it’s called a duck but it walks like a chicken and talks like a chicken, it’s probably a chicken.
For example,
- “We need to keep quotes, but we won’t be using Opportunities, or Products or sending Quote’s out of Salesforce”
- It’s probably not the Quote object
- “We need to track Requests, with email interactions and pass it back and forth between people”
- I think you mean ‘Case’
7. Define the user stories in a way that expresses a requirement with context and justification.
- Usually in a standard form: ‘AS A \<Job Role\> I WANT TO <some business process> SO THAT I can <achieve some outcome>’
- For sample user stories refer #2
8. Rename Object, Tab, and Field Labels to make your users feel at home.
9. Get into continuous refactoring mindset:
What is right today might not be right tomorrow, so don’t be afraid to refactor/redesigning your Data Model to suit your needs, and use tools like Dataloader to massage your existing data to match new Data Model design.
10. Be thoughtful about your naming conventions:
The way you name something can live with you forever. Remember to add descriptions & helptext everywhere it is possible to self document your org.
Here are a few resources to learn more than just tips and become a Pro at scalable data modelling:
- Data Modelling Basics - Trailhead Module
- Build a Data Model for a Recruiting App - Trailhead Project
- Play by Play: Denormalize Your Thinking About Salesforce Data Modeling
- Salesforce Data Models for Pros: Simplifying The Complexities
Want to get your data model right with a partner? Work with ProQuest Consulting today!













